시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq)?
1. Seq2Seq Architecture

2개의 모듈, Encoder와 Decoder로 구성되어 있어서 Encoder-Decoder 모델이라고도 부른다.
시퀀스-투-시퀀스(Sequence-to-Sequence)는 입력된 시퀀스로부터 다른 도메인의 시퀀스를 출력하는 다양한 분야에서 사용되는 모델로 예를 들어 챗봇(Chatbot)과 기계 번역(Machine Translation)가 대표적인 사용 예이다.
아키텍쳐의 내부를 살펴보면 두 개의 RNN 아키텍처로, 입력 문장을 받는 RNN 셀을 인코더라고 하고, 출력 문장을 출력하는 RNN 셀을 디코더라고 한다. 또한 인코더와 디코더 내부는 LSTM 셀 또는 GRU 셀들로 구성된다. 인코더와 디코더에는 RNN, LSTM, GRU 등 다양한 RNN 계열 모델이 들어갈 수 있는데 이 중 LSTM이 가장 성능이 좋다고 한다.
인코더
입력 문장을 이해하고 핵심 정보를 추출하는 부분이다. 마치 문장을 꼼꼼히 읽고 중요한 내용만 요약하는 것과 비슷한데, 이 과정에서 LSTM은 문장의 단어들을 순서대로 읽으면서,각 단어의 의미와 문맥을 파악하여 hidden state를 만들어낸다. 마지막 단어까지 읽고 나면, LSTM은 최종 hidden state를 갖게 되는데, 이것이 바로context vector로, context vector는 원래 문장의 핵심 정보를 압축해서 담고 있는 벡터이다.
디코더
인코더가 만든 context vector를 바탕으로 새로운 문장을 생성하는 부분이다. context vector를 참고하여 원래 문장의 의미를 살리면서 새로운 문장을 만들어낸다.
인코더와 디코더 자세히 살펴보기

인코더 블록
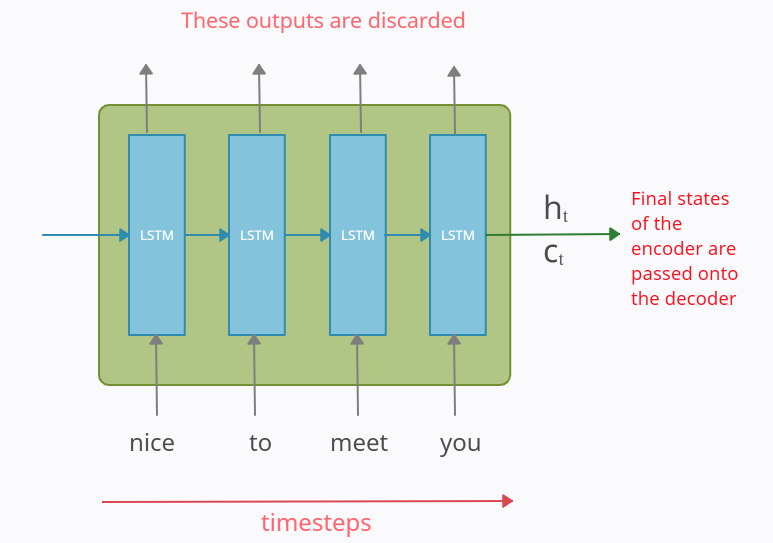
위의 사진은 LSTM셀이 시간 축을 기준으로 나열한 예시이다. 입력은 word Tokenization을 통해 단어 단위로 쪼개진 후 LSTM 셀의 각 시점(t)의 입력으로 들어간다.
인코더는 단어 토큰을 받아 모든 정보를 포함하는 hidden state(h)와 cell state(c)를 만든다. 이 state
인코더에서 LSTM 셀들의 출력값들은 버려진다.
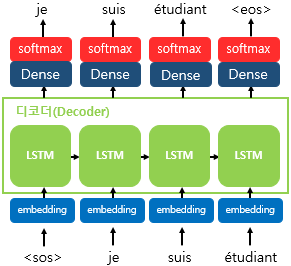
디코더 RNN 셀의 출력으로 다양한 단어에 대한 벡터 값이 나올 것이다. 그중 확률이 가장 높은 단어를 선택하기 위해 softmax를 취해준다. 이를 통해 최종 예측 단어를 생성한다.
이제 마무리로 seq2seq에 대해 정리해보겠다. seq2seq는 인코더와 디코더로 구성되어 있으며, 인코더는 입력 문장의 정보를 압축하는 기능을 한다. 압축된 정보는 Context 벡터라는 형식으로 디코더에 전달된다. 디코더는 훈련 단계에서는 교사 방식(teaching force)으로 훈련되며, 테스트 단계에서는 인코더가 전달해준 Context 벡터와 를 입력값으로 하여 단어를 예측하는 것을 반복하며 문장을 생성한다.
이상으로 seq2seq에 대해 알아보았다.
Reference
- https://medium.com/analytics-vidhya/encoder-decoder-seq2seq-models-clearly-explained-c34186fbf49b
'AI' 카테고리의 다른 글
| Transformer - Structure, Posititonal Encoding (0) | 2024.06.20 |
|---|---|
| LSTM의 Cell State와 Gate별 특징 (0) | 2024.06.19 |
| RNN(Recurrent Neural Networks) (1) | 2024.06.19 |
| 케라스 하이퍼파라미터 튜닝(Keras hyperparameter Tuning) feat. 케창딥 13장 (0) | 2024.06.14 |
| Semantic Segmentation 기반 아웃포커싱: Depth Estimation, Instance Segmentation을 통한 정확도 향상에 관하여 (0) | 2024.06.05 |


