
Transformer에 앞서, Attention 매커니즘 이란?
어텐션 메커니즘(Attention Mechanism)은 인공 신경망 모델이 입력 데이터의 특정 부분에 더 집중하도록 하는 기술로, 인간이 정보를 처리할 때 중요한 부분에 집중하는 것과 유사하게, 모델이 입력 시퀀스의 모든 부분을 동일하게 처리하는 대신, 특정 부분에 더 많은 가중치를 부여하여 중요한 정보를 효과적으로 추출하고 처리하는 방법입니다.
1) Attention 매커니즘의 등장 배경

RNN 기반의 기존 Seq2Seq 기반의 번역, 요약 방식은 3가지 문제점이 있었습니다.
- 학습시간(🐢 느림) : RNN은 순차적으로 입력을 처리해야하기에 병렬화가 불가능했고, 대규모의 데이터셋의 경우 학습 시간이 지나치게 길어졌습니다.
- 정보소실(🕳️ 까먹음) : RNN은 단어를 순차적으로 처리하면서, 이전 단어의 정보를 '은닉 상태(hidden state)'라는 벡터에 저장합니다. 하지만 이 은닉 상태는 고정된 크기로 제한되어 있어, 문장이 길어질수록 앞부분 단어의 정보를 점점 잊어버리게 됩니다. 이를 '장기 의존성 문제'라고 합니다.
- 기울기소실(📉 흐릿해짐) : 긴 문장을 학습할 때, 앞부분 단어에 대한 기울기가 뒷부분까지 전달되는 과정에서 점점 작아지는 현상이 발생합니다. 이를 'Vanishing Gradient Problem'이라고 합니다.
이 문제에 대한 해결책으로 등장한 기술이 어텐션 메커니즘입니다. 트랜스포머는 어텐션 메커니즘을 기반으로 하는 모델로, RNN의 정보 손실 및 기울기 소실 문제를 해결하고 병렬 처리를 가능하게 하여 학습 속도를 크게 향상시켰습니다.
transformer의 구조를 살펴보자

트랜스포머의 전체 구조를 보면 위와 같이 구성되어 있습니다.

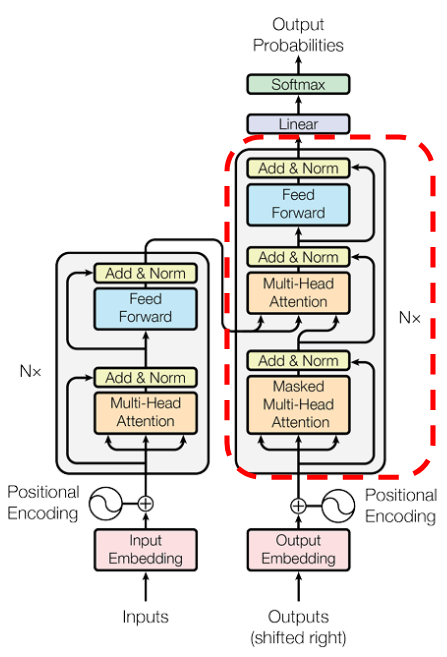
약간 복잡해보이지만, 크게보면 인코더 층(Encoder layer, 왼쪽) 과 디코더 층(Decoder layer, 오른쪽)으로 나눌 수 있습니다. 인코더는 입력 문장을 임베딩하고 의미를 파악하는 역할을 하고, 디코더는 전달 받은 정보를 기반으로 문장을 생성합니다. 또한 빨간색으로 표시된 각각의 encoder, decoder 블럭은 N개씩 반복 배치 됩니다. 즉, 인코더층 N개와 디코더 층 N개가 이어집니다. 만약 레이어가 2개씩 반복된다면 아래와 같이 구성됩니다.

인코더(encoder) 구성
인코더 층에는 2개의 서브 레이어가 있습니다.
- Multi-Head Attention(Encoder Self-Attention)
- Feed Forward
디코더(decoder) 구성
디코더 층에는 3개의 서브레이어가 있습니다.
- Masked Multi-Head Attention(Decoder Self-Attention)
- Multi-Head Attention(Encoder-Decoder self Attention)
- 피드포워드 신경망
이제 input 부터 output까지 하나하나 들어가 봅시다.
1. Embedding
컴퓨터는 한글 혹은 영어 문자 그대로를 학습할 수 없습니다. 데이터를 넣어줄 때, 컴퓨터가 학습할 수 있도록 컴퓨터가 읽은 수 있게 숫자로 변환해서 데이터를 넣어주어야 합니다.
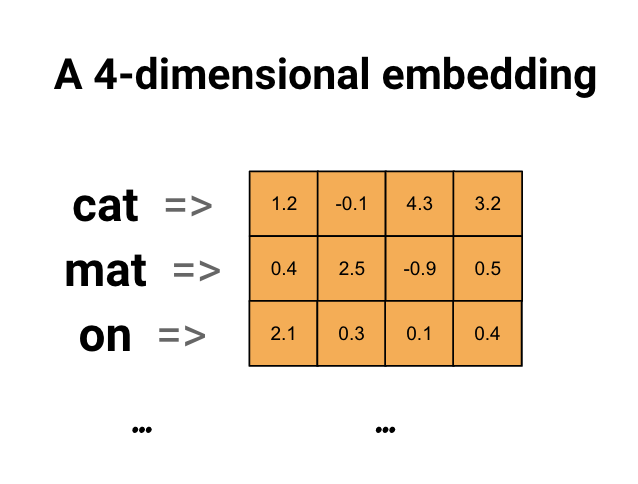
Embedding이란? 단어 임베딩(Word Embedding)은 자연어 처리(NLP)에서 단어를 컴퓨터가 이해할 수 있는 숫자 벡터로 표현하는 방법입니다. 각 단어를 고차원의 한 점으로 표현하며, 단어의 의미와 문맥을 표현하는 방법입니다.
2. Posititonal Encoding
1) Posititonal Encoding을 하는 이유

트랜스포머 모델은 단어 임베딩을 입력으로 받아 처리하는데, 이 임베딩에는 단어의 의미 정보만 담겨 있고 단어의 순서 정보는 없습니다. 하지만 자연어 처리에서 단어의 순서는 문장의 의미를 파악하는 데 매우 중요한 역할을 합니다.
2) Posititonal Encoding을 위한 삼각함수(sine, cosine)
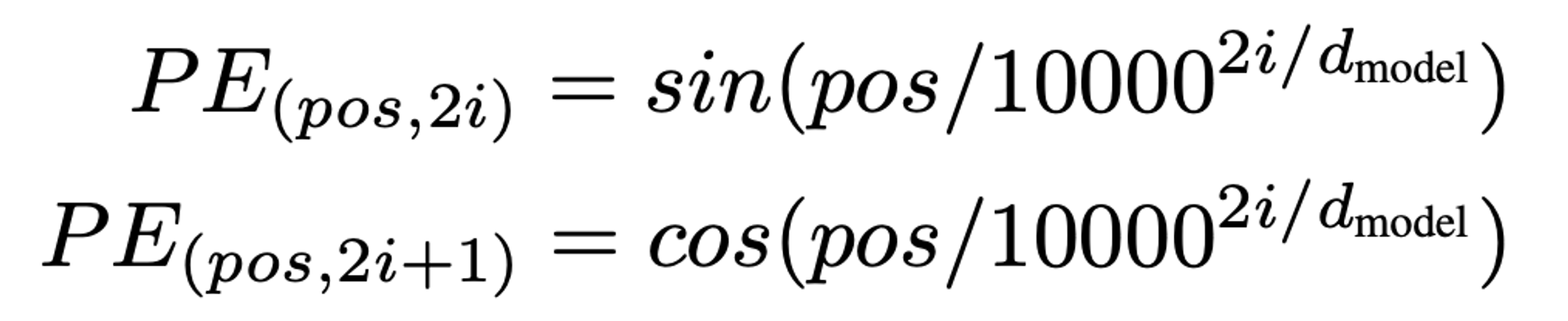
Transformer 가 등장하게된 논문인 'Transformer All you need'을 보면, 아래와 같은 수식으로 Positional Encoding을 계산합니다.
- d: 임베딩 차원
- p : p 번째 단어
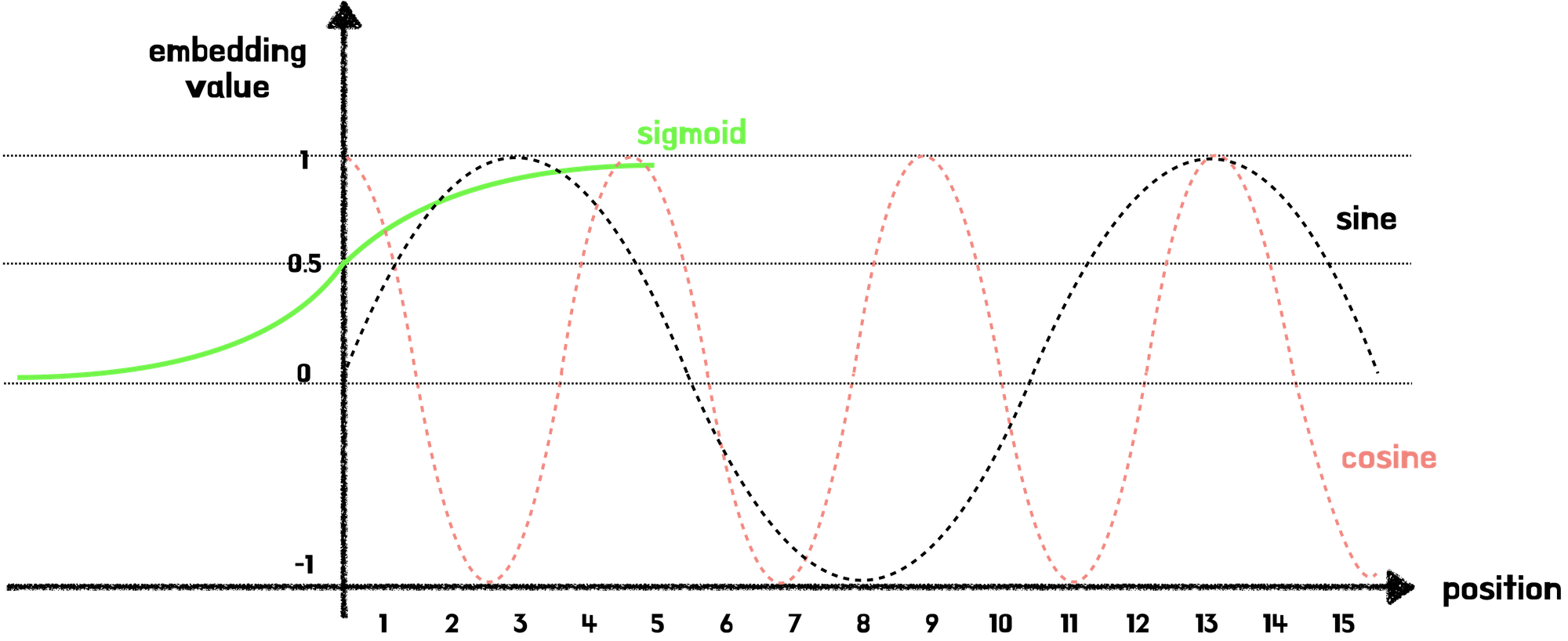
sine, cosine 함수는 ~1 ~ 1 사이의 주기함수로 값이 너무 커지지도, 작아아지지도 않으며, 주기적인 특성을 가지므로, 각 단어 위치에 대해 고유한 값을 생성할 수 있다는 점에서 Positional Encoding 벡터 계산에 쓰였습니다.
I am a Robot 이란 데이터에 대하여 Poisitional Encoding Matrix를 구현하면 아래와 같습니다. (계산 편의상 10000 을 100으로 줄여서 행렬로 나타냈다고 합니다.)

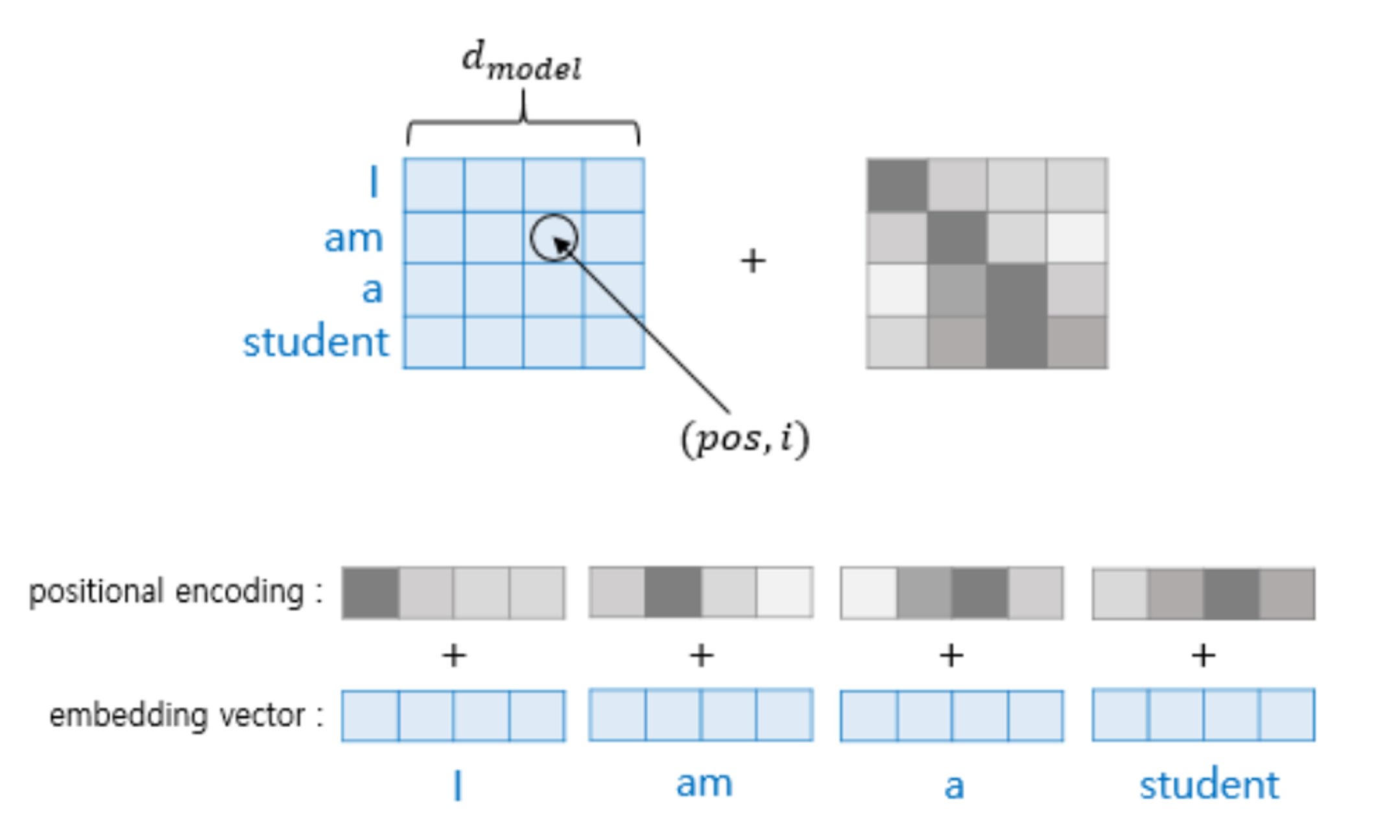
pos는 입력 문장에서의 임베딩 벡터의 위치를 나타내며, i는 임베딩 벡터 내의 차원의 인덱스를 의미합니다. 중요한 점은, 임베딩 벡터 내의 각 차원의 인덱스가 짝수인 경우에는 사인 함수의 값을 사용하고 홀수인 경우에는 코사인 함수의 값을 사용합니다. 또한 d_model은 트랜스포머의 모든 층의 출력 차원을 의미하는 transformer의 하이퍼파라미터입니다. 위의 사진에서는 4의 크기로 볼 수 있습니다.
reference
- https://nlpinkorean.github.io/illustrated-transformer/
- https://arxiv.org/pdf/1706.03762
- https://codingopera.tistory.com/43
- https://velog.io/@jhbale11/어텐션-매커니즘Attention-Mechanism이란-무엇인가
- https://blog.skby.net/어텐션-메커니즘-attention-mechanism/
- https://ratsgo.github.io/nlpbook/docs/language_model/tr_technics/
'AI' 카테고리의 다른 글
| Transformer (Multi-head Attention) (0) | 2024.06.22 |
|---|---|
| Transformer (Self-Attention) (0) | 2024.06.22 |
| LSTM의 Cell State와 Gate별 특징 (0) | 2024.06.19 |
| RNN(Recurrent Neural Networks) (1) | 2024.06.19 |
| 시퀀스-투-시퀀스(Sequence-to-Sequence) (0) | 2024.06.18 |



