

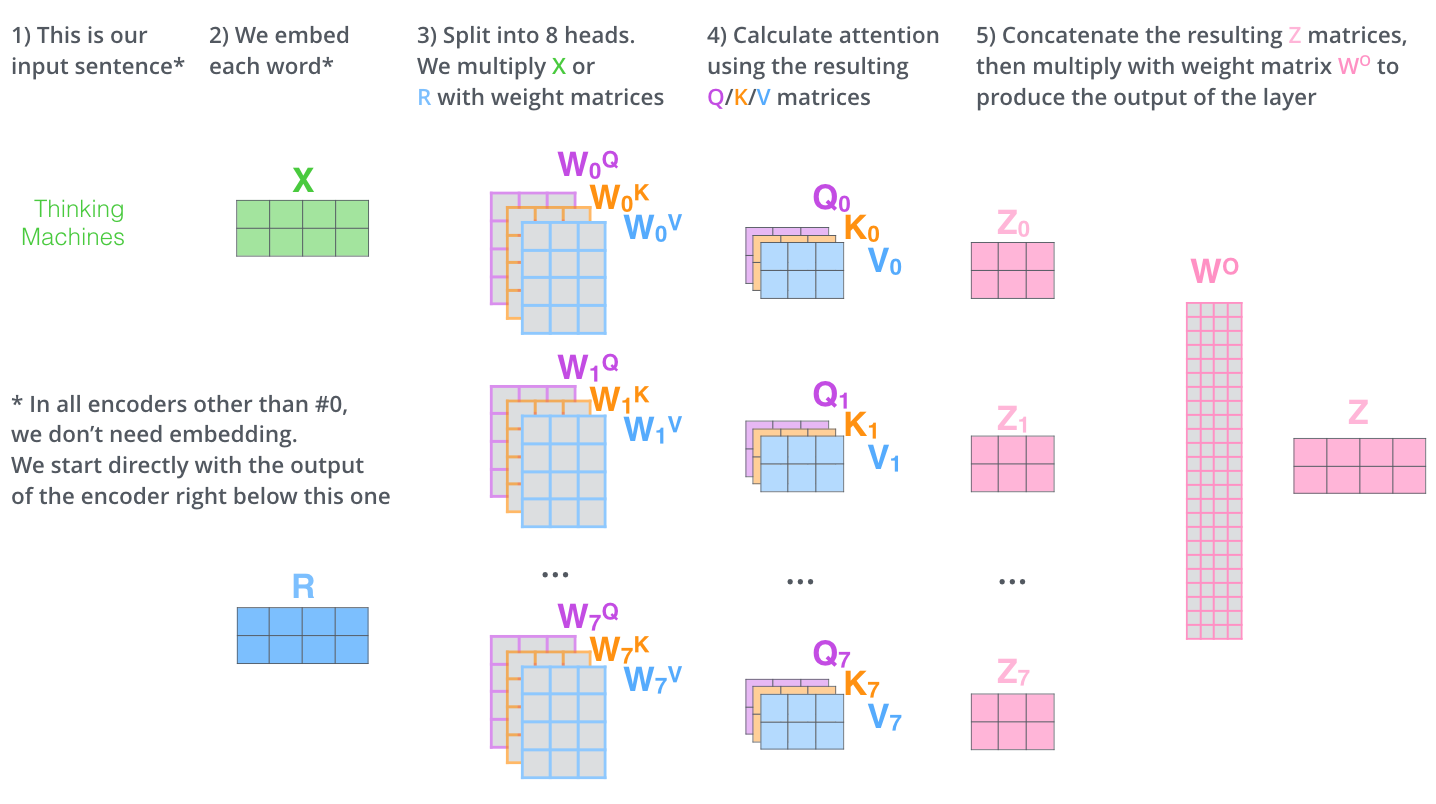
Transformer의 Attention은 모두 Multi-head attention이 쓰였습니다. 트랜스포머 연구진은 한 번의 어텐션을 하는 것보다 여러번의 어텐션을 병렬로 사용하는 것이 더 효과적이라고 판단하였는데요. 한번 살펴봅시다.
Multi-head Attention
Self-Attention의 모델을 먼저 살펴봅시다.
Self-Attention 모델

Self-Attention에서는 하나의 Sequence에 각각 하나씩의 Query, Key, Value값을 구하고, Attention을 수행하였습니다. Multi-head Attention에서는 여러번의 어텐션을 병렬로 사용하는데요.
Multi-head Attention 모델

Multi-head Attention을 보시면 여러번의 어텐션이 병렬로 연상되는 것을 보실 수 있습니다. 논문에서는 하이퍼파라미터인 num_heads 값을 8개로 지정하여, 8개의 병렬 Attention이 이루어지게됩니다. 즉 Self-Attention을 동시에 여러번 수행하는 것으로 여러 head가 독자적인 Self-Attention을 계산한다는 의미입니다.
1. Multi Query, Key, Value

Multi-head Attention을 위해 여러번의 Self-Attention을 병렬로 여러번 수행하기 위해, 서로다른 Query, Key, Value를 위한 가중치행렬 Wn을 8번 수행합니다.
2. Scaled Dot-Product Attention

self-Attention 계산을 다른 가중치 행렬 Wn으로 8번을 생성하면, 결과적으로 8개의 다른 Attention 결과 행렬 Z가 생기겠네요. 하지만 이후에 있는 feed-forward layer를 위해 8개의 Z행렬이 아닌 각각의 문장에 대한 한개의 행렬이 필요합니다. 그래서 저희는 한개의 행렬로 변환해주어야 합니다.
3. Concatenate all the attention heads & Linear

8개의 Z행렬을 1개로 압축하기 위해, 추가 가중치행렬 WO를 곱해줍니다. 그렇다면 FFNN 로 보낼 수 있는 1개의 Z matrix를 구할 수 있겠네요.
Summary
Reference
'AI' 카테고리의 다른 글
| 생물학적 뉴런과 인공 신경망 (1) | 2024.07.03 |
|---|---|
| Transformer (Self-Attention) (0) | 2024.06.22 |
| Transformer - Structure, Posititonal Encoding (0) | 2024.06.20 |
| LSTM의 Cell State와 Gate별 특징 (0) | 2024.06.19 |
| RNN(Recurrent Neural Networks) (1) | 2024.06.19 |



