Aiffel 리서치 과정을 하면서 Semantic Segmentation을 위해 학습된 DeepLab mode을 가져와 Outfocusing을 실습하였음.
학습 과정 중 DeepLab을 활용한 Semantic Segmentation의 단점(1. 연산량이 많아 시간이 많이 걸림 2. 경계(디테일) 부분에서의 보케가 아쉬움)을 알게 되었고 다른 Out focusing 기법을 찾아보다가, depth Estimation 기법을 알게 되어서 두 개념을 비교해 보고 정리해보았음
들어가기 전 사전 지식, CV(컴퓨터비전)의 가장 중요한 문제들
CV에서 다루는 주요 문제들을 소개하면 크게 Classification, Localization/Detection, Segmentation로 나뉨
1. Classification
이미지 전체 또는 이미지 내 특정 영역에 나타나는 객체가 어떤 클래스(범주)에 속하는지 판별하는 문제.
ex) 이미지에 고양이가 있는지, 개가 있는지, 아니면 둘 다 없는지를 분류하는 것.
2. Localization/Detection
이미지 내에 객체가 존재하는 위치를 찾고, 해당 객체를 사각형 박스(Bounding Box)로 표시하는 문제. 객체의 종류까지 분류하는 것을 Object Detection이라고 함
3. Segmentation
이미지를 픽셀 단위로 분류하여 각 픽셀이 어떤 객체에 속하는지 파악하는 문제 Semantic Segmentation, 각 픽셀을 미리 정의된 클래스(예: 사람, 자동차, 하늘)에 따라 분류 Instance SegmentationSemantic Segmentation에서 더 나아가, 동일한 클래스에 속하는 객체들을 각각 구분하여 분할
1. Semantic Segmentation 설명


Semantic Segmentation은 CV(컴퓨터 비전) 분야에서 가장 핵심적인 Task로 이미지 내의 모든 픽셀을 각각 특정 클래스(예: 사람, 자동차, 건물)에 할당하는 작업
좀 더 자세히 살펴보면,

모델 학습 후 카메라 영상에 대해 사진을 의미론적으로 분할하였고, class별로 색깔을 입혀 만든 예시이다.
차, 사람, 나무, 하늘, 도로 등 class 별로 나누어 구분이 된다.
2. Semantic Segmentation 기반 outfocucing 실습
2-0) 목표
아래 사진에서 소라는 객체와 배경를 segment 한 뒤 배경를 blur처리하여 outfocucing을 진행하였다

2-1) 모델 가져오기
pacalvoc 데이터로 학습된 DeepLab이라는 Segmentation 모델을 이용해 기능 구현을 진행하였음
아래 링크에서 학습된 DeepLab 모델을 가져와 모델을 생성할 수 있음
https://github.com/ayoolaolafenwa/PixelLib
PASCAL VOC 데이터 관련 정보 링크
http://host.robots.ox.ac.uk/pascal/VOC/
주요 코드 소개
# PixelLib가 제공하는 모델의 url
model_url = 'https://github.com/ayoolaolafenwa/PixelLib/releases/download/1.1/deeplabv3_xception_tf_dim_ordering_tf_kernels.h5'
# 모델 다운로드
urllib.request.urlretrieve(model_url, model_file) #model_file: 원하는 다운로드 위치
#semantic segmentation 수행 클래스 인스턴스 생성
model = semantic_segmentation()
# pascal voc에 대해 훈련된 예외 모델(model_file)을 로드하는 함수를 호출
model.load_pascalvoc_model(model_file) #model_file: 설치한 모델 위치
2-2) image segmentation
가져온 모델을 통해 사진을 넣고 이미지를 분할 후 Out Focusing을 위한 작업을 진행하였음
이미지 분할
#이미지 분할
segvalues, output = model.segmentAsPascalvoc(img_path) #img_path 원하는 사진 위치이미지를 분할하면 segvalues, output 값을 받아올 수 있는데 각각을 살펴보자
- segvalues 안에는 class_ids, masks 값이 dictionary 형태로 들어있음
- class_ids : 사진에 있는 세그먼트 클래스의 이름 ('person', 'car', 'background'등)
- masks : 픽셀값(false, Ture)으로 구성
- output (분할 결과 이미지) : NumPy 배열 (ndarray)
output 출력 확인
#output 출력 확인
plt.imshow(output)
plt.show()
- 소 객체와 배경이 나누어 진 것을 알 수 있음
데이터 라벨 확인
#pascalvoc 데이터의 라벨종류
LABEL_NAMES = [
'background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus',
'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike',
'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tv'
]
#segvalues에 있는 class_ids를 담겨있는 값을 통해 pacalvoc에 담겨있는 라벨을 출력
for class_id in segvalues['class_ids']:
print(LABEL_NAMES[class_id])>> background
>> cow
- 사진이 cow, backgournd 두가지로 segment된 것을 확인할 수 있음
color_mask 만들기
seg_color = (0,128,64) # 색상순서 변경
#array([ 64, 128, 0]) : 소를 나타내는 color_map
#색상순서 변경 - colormap의 배열은 RGB 순이며 output의 배열은 BGR 순서로 채널 배치가 되어 있음
seg_map = np.all(output==seg_color, axis=-1)
#output의 마지막 column인 출력 색상을 비교하여,픽셀 별로 색상이 seg_color와 같다면 1(True), 다르다면 0(False)
plt.imshow(seg_map, cmap='gray')
plt.show()
# True과 False인 값을 각각 255과 0으로 바꿔줌
img_mask = seg_map.astype(np.uint8) * 2552-3) blur 처리하기
img_show = img_orig.copy() #원본 이미지 가져오기
img_orig_blur = cv2.blur(img_orig, (15,15)) #blur처리
#blurring kernel size를 뜻함
# 이미지 색상 채널 변경 후 출력(BGR 형식을 RGB 형식으로 변경)
plt.imshow(cv2.cvtColor(img_orig_blur, cv2.COLOR_BGR2RGB))
plt.show()
2-4) Outfocusing 처리
# 이미지 색상 채널 변경 (BGR 형식을 RGB 형식으로 변경)
img_mask_color = cv2.cvtColor(img_mask, cv2.COLOR_GRAY2BGR)
# 배경 255 소는 0 으로 만들기
# 각 픽셀에 대해 비트 값을 반전
img_bg_mask = cv2.bitwise_not(img_mask_color)
# cv2.bitwise_and() : 두 이미지의 픽셀 비트 비교 후 둘다 1인 경우에만 1, 아닌경우 0을 출력
# 0과 어떤 수를 bitwise_and 연산을 해도 0이 되기 때문에
img_bg_blur = cv2.bitwise_and(img_orig_blur, img_bg_mask)
plt.imshow(cv2.cvtColor(img_bg_blur, cv2.COLOR_BGR2RGB))
plt.show()
#img_mask_color에서 소 객체 부분의 픽셀을 기존 사진으로 할당, 배경부분을 blur처리된 사진으로 할당
img_concat = np.where(img_mask_color==255, img_orig, img_bg_blur)
plt.imshow(cv2.cvtColor(img_concat, cv2.COLOR_BGR2RGB))
plt.show()2-5) 결과를 통한 DeepLab 모델의 Semantic Segmentation 문제점 분석

위 사진에서 보면 물체의 경계 부분 특히 소의 다리와 같은 얇고 복잡한 형태의 물체의 경계 부분의 객체인식이 부정확함. 그이유를 보면DeepLab 모델은 atrous convolution을 사용하여 receptive field를 넓히고, 다양한 크기의 객체를 잘 인식하도록 설계되었으나 물체의 경계 부분을 세밀하게 분할하는 데에는 어려움을 겪음. 또한 이는 다른 segmeentation 모델들도 공통적으로 겪는 문제라고 함.
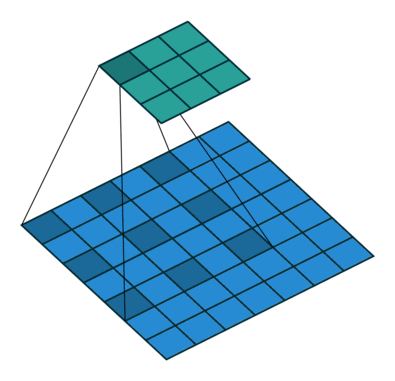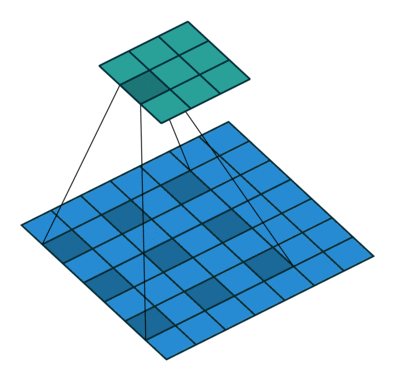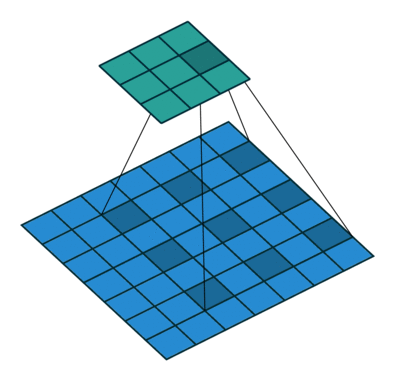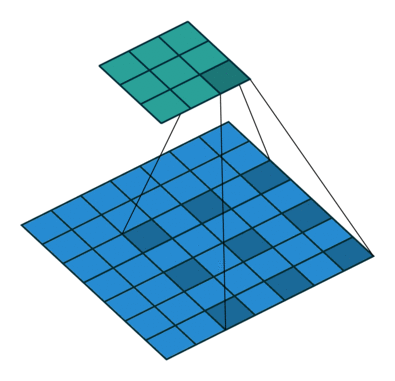
DeepLab 모델의. Semantic Segmentation 문제점을 종합해보면 아래와 같이 종합할 수 있음.
- 세밀한 경계 표현의 문제 : DeepLab 모델은 atrous convolution을 사용하여 receptive field를 넓히고, 다양한 크기의 객체를 잘 인식하도록 설계되었으나, 물체의 경계 부분을 세밀하게 분할하는 데에는 어려움을 겪음. 특히 얇거나 복잡한 형태의 물체는 경계가 부정확하게 나타날 수 있음.
- 실시간 처리의 어려움: DeepLab 모델은 높은 정확도를 위해 복잡한 구조를 가지고 있어 학습시간이 오래 걸리는 것을 확인하였음. 특히, 고해상도 이미지나 동영상을 처리해야 하는 경우에는 속도가 더 느려질 것으로 예상됨.
- 동일한 객체에 다른 Out-focusing 적용이 어려움 : Semantic Segmentation의 경우 객체를 class 단위로 나누기 때문에 같은 객체는 동일한 class로 인식하므로, 동일한 객체에 서로 다른 Out-focusing 적용이 어려움.
실제 Outfocusing에 사용되는 기술들에는 이러한 문제점들이 어떤 방식으로 보안되었는지 찾아본 결과. Depth Estimation, Instance Segmentation을 활용하여 정확도를 향상할 수 있다는 것을 알게되었음.
3. Depth Estimation, Instance Segmentation 설명
Depth Estimation
Depth Estimation은 이미지나 비디오에서 각 픽셀의 카메라로부터의 거리 정보를 추정하는 기술 즉, 2차원 이미지를 분석하여 3차원 공간 정보를 복원하는 과정

Depth Map
Depth Estimation의 결과물은 깊이 맵(Depth Map)으로 표현되는데, 깊이 맵은 입력 이미지와 동일한 크기를 가지는 2차원 이미지이며, 각 픽셀 값은 해당 픽셀의 카메라로부터의 거리를 나타냄.
출처 : https://skk095.tistory.com/4
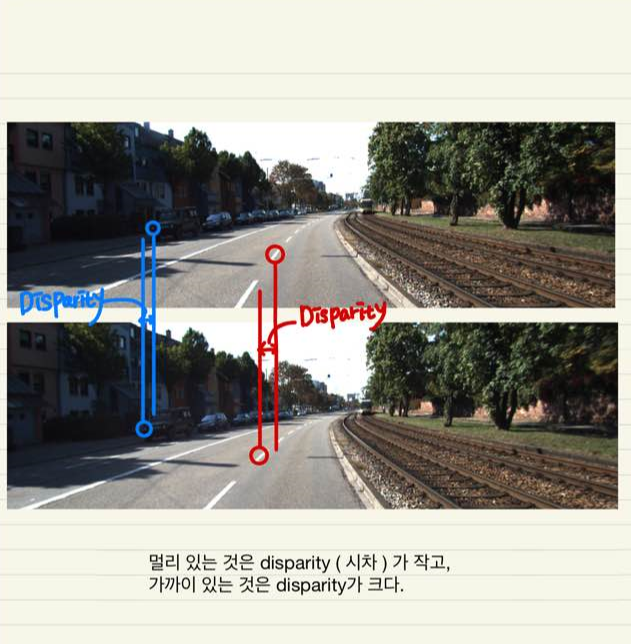
Depth Map의 계산 방식은,
image에 대해 두 image(left image, right image)가 있어야 하며, 같은 공간에 대해서의 disparity(차이)를 통해 Depth를 알아내는 방식.
Mono Depth Estimation을 활용하면 하나의 left image를 통해서도 Depth 알아낼 수 있다고 함.
Instance Segmentation
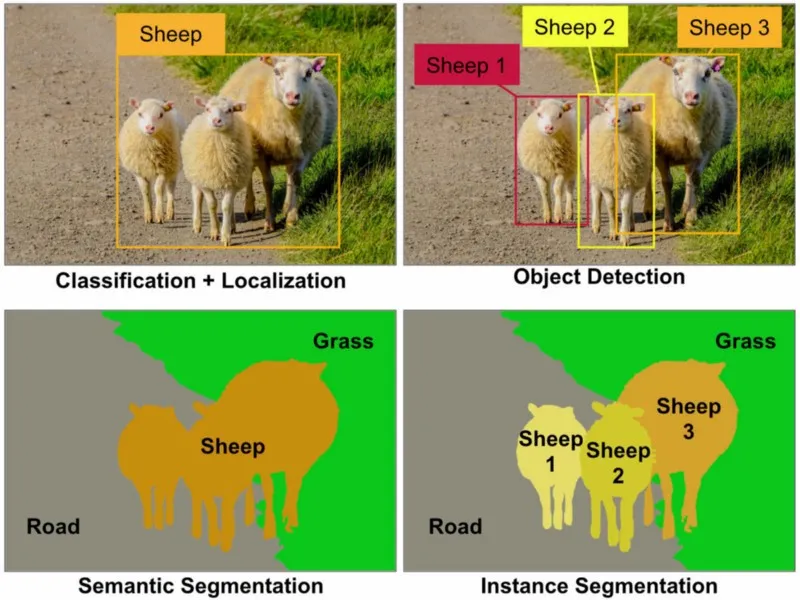
Instance Segmentation은 Semantic Segmentation에서 더 나아가, 이미지 내에서 동일한 클래스에 속하는 각각의 객체들을 개별적으로 식별하고 분할하는 기술
4. Depth Estimation, Instance Segmentation을 활용한 Out-focusing 정확도 향상 방법에 대하여
Depth Estimation for Out-focusing
1. Depth map을 활용하여 피사체와 배경을 더욱 정확하게 분리
2. Depth map을 활용하여 머리카락, 옷 주름 등 복잡한 경계를 가진 피사체를 분할 시 유용
3. Depth map 기반으로 픽셀별 블러 강도를 조절할 수 있음
Instance Segmentation for Out-focusing
1. 이미지 내 여러 피사체를 각각 분할하고, 각 피사체에 대해 개별적으로 아웃포커싱 효과를 적용
2. Instance Segmentation을 통해 얻은 마스크 정보를 활용하여 더욱 정확한 아웃포커싱 결과 도출
3. 특정 클래스의 객체에만 아웃포커싱 효과를 적용하거나, 클래스별로 다른 블러 강도를 적용하는 등 다양한 효과를 연출 가능
즉, Depth Estimation, Instance Segmentation를 활용하면 Out-focusiong의 정확도를 더욱 향상시킬 수 있으며, sementic segmentation을 단일로 사용한 model 보다 더욱 효과적임
위 기술들을 융합한 모델이 있나 찾아보았고, SOSD-NET이라는 이미지처리 model을 알게 되었음.
SOSD-NET
자료를 찾아보던 중 Depth Estimation과 sementic segmentation 을 동시에 수행하는 SOSD-NET 을 알게 되었음. Depth Estimation과 sementic segmentation 을 픽셀 단위로 동시에 학습한다고 함
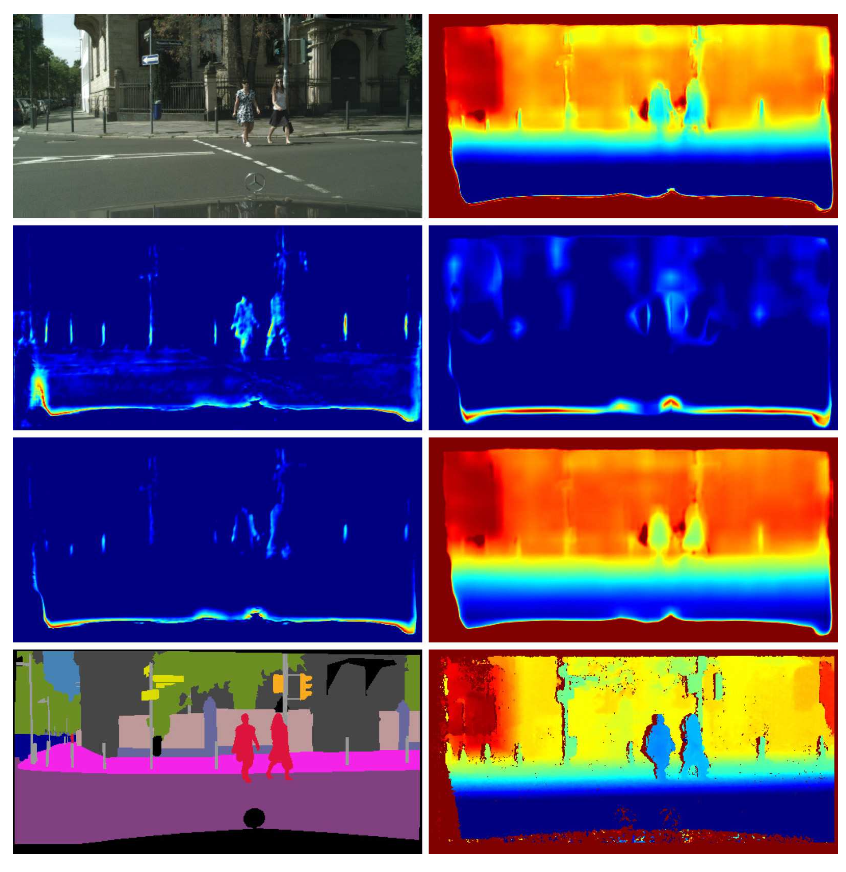
Depth Estimation과 sementic segmentation을 동시에 수행하는데, Depth map을 통하여 3D 표현을 활용하고 segmentation을 통해 더욱 정교한 segment가 가능하다고 함.
논문링크 : https://arxiv.org/pdf/2101.07422
결론
Depth Estimation, Instance Segmentation 등 다양한 기술을 융합한다면 더욱 정교하고 정확한 Out-focusing이 가능하며, SOSD-NET 과 같이 다양한 기술들을 융합하여 이미지를 처리하는 모델들이 활용되고 있음.
'AI' 카테고리의 다른 글
| Transformer - Structure, Posititonal Encoding (0) | 2024.06.20 |
|---|---|
| LSTM의 Cell State와 Gate별 특징 (0) | 2024.06.19 |
| RNN(Recurrent Neural Networks) (1) | 2024.06.19 |
| 시퀀스-투-시퀀스(Sequence-to-Sequence) (0) | 2024.06.18 |
| 케라스 하이퍼파라미터 튜닝(Keras hyperparameter Tuning) feat. 케창딥 13장 (0) | 2024.06.14 |


